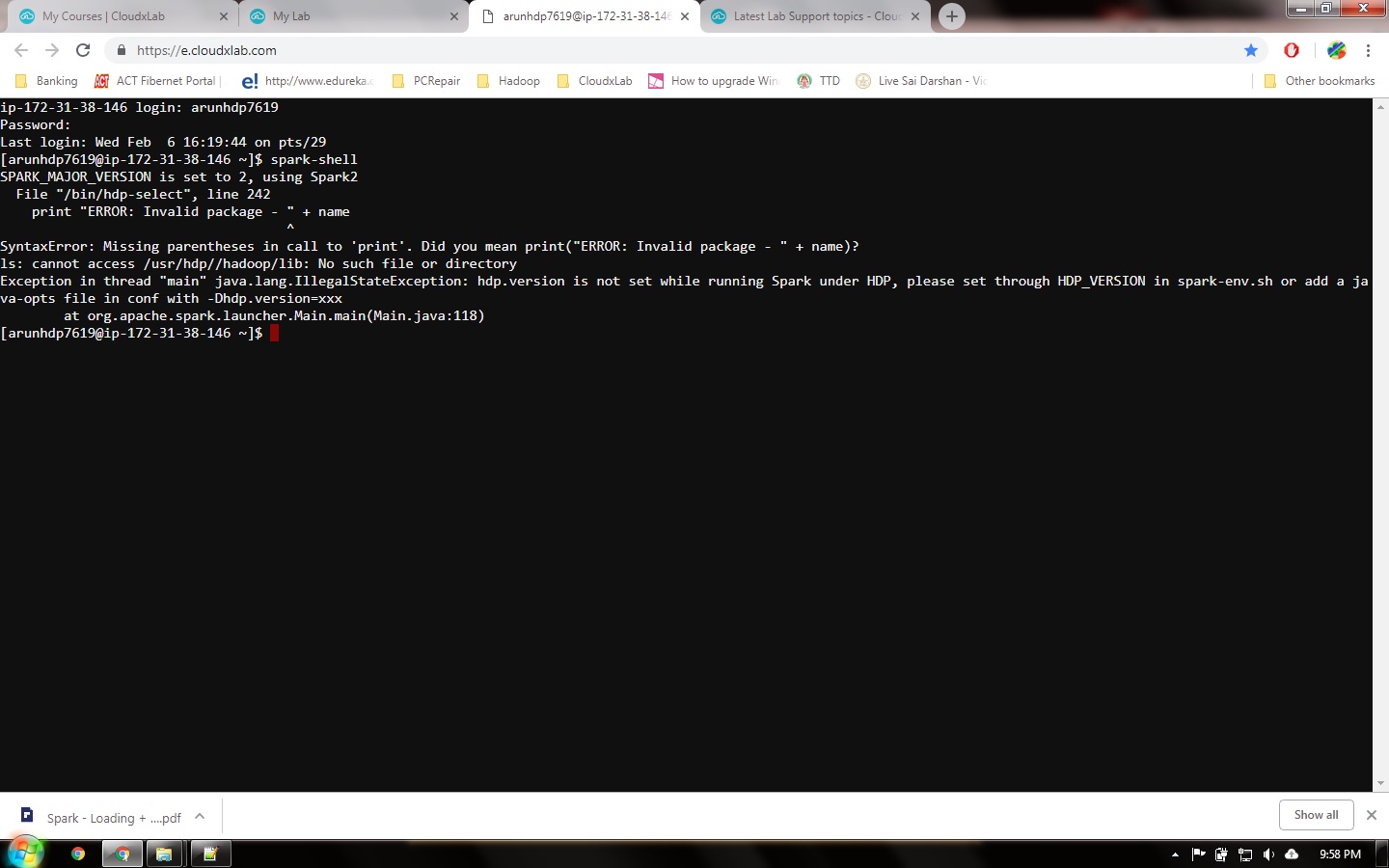
How do I get out of spark shell?
- Navigate to the Spark-on-YARN installation directory, and insert your Spark version into the command. cd...
- Issue the following command to run Spark from the Spark shell: On Spark 2.0.1 and later: ./bin/spark-shell --master yarn...
How do I exit a spark shell?
If you type "exit()" in spark shell, it is equivalent to a Ctrl+C and does not stop the SparkContext. This is used very commonly to exit a shell, and it would be good if it is equivalent to Ctrl+D instead, which does stop the SparkContext. Similarly, what is spark shell command? Apache Spark - Deployment.
How do I use spark-shell?
It allows you to create Spark programs interactively and submit work to the framework. You can access the Spark shell by connecting to the master node with SSH and invoking spark-shell. For more information about connecting to the master node, see Connect to the master node using SSH in the Amazon EMR Management Guide.
What is the spark shell?
The Spark shell is based on the Scala REPL (Read-Eval-Print-Loop). It allows you to create Spark programs interactively and submit work to the framework. You can access the Spark shell by connecting to the master node with SSH and invoking spark-shell.
How do I get Started with spark?
This tutorial provides a quick introduction to using Spark. We will first introduce the API through Spark’s interactive shell (in Python or Scala), then show how to write applications in Java, Scala, and Python. To follow along with this guide, first, download a packaged release of Spark from the Spark website.
How do you open the spark shell?
Launch Spark Shell (spark-shell) Command Go to the Apache Spark Installation directory from the command line and type bin/spark-shell and press enter, this launches Spark shell and gives you a scala prompt to interact with Spark in scala language.
What is spark shell command?
Spark Shell Commands are the command-line interfaces that are used to operate spark processing. Spark Shell commands are useful for processing ETL and Analytics through Machine Learning implementation on high volume datasets with very less time.
How do you open the spark shell in Pyspark?
Launch PySpark Shell Command Go to the Spark Installation directory from the command line and type bin/pyspark and press enter, this launches pyspark shell and gives you a prompt to interact with Spark in Python language.
How does spark shell work?
The shell acts as an interface to access the operating system's service. Apache Spark is shipped with an interactive shell/scala prompt with the interactive shell we can run different commands to process the data.
How do you stop a command in Spark shell?
1 Answer. Pressing Ctrl+D will terminate the Spark Session and exit the Spark shell.
How do you exit a shell in Scala?
Exit From Scala ShellFor Linux, use the Ctrl + d + enter keys combination.For Windows, use the Ctrl + z + enter keys combination.:q.:quit.Ctrl + c.
How do I open PySpark shell in Windows?
In order to work with PySpark, start Command Prompt and change into your SPARK_HOME directory. a) To start a PySpark shell, run the bin\pyspark utility. Once your are in the PySpark shell use the sc and sqlContext names and type exit() to return back to the Command Prompt.
How do I start PySpark?
How to Get Started with PySparkStart a new Conda environment. ... Install PySpark Package. ... Install Java 8. ... Change '. ... Start PySpark. ... Calculate Pi using PySpark! ... Next Steps.
How do I run Python Spark?
Generally, PySpark (Spark with Python) application should be run by using spark-submit script from shell or by using Airflow/Oozie/Luigi or any other workflow tools however some times you may need to run PySpark application from another python program and get the status of the job, you can do this by using Python ...
How do I run Spark app?
Getting Started with Apache Spark Standalone Mode of DeploymentStep 1: Verify if Java is installed. Java is a pre-requisite software for running Spark Applications. ... Step 2 – Verify if Spark is installed. ... Step 3: Download and Install Apache Spark:
How do I use Spark SQL Spark shell?
ProcedureStart the Spark shell. dse spark.Use the sql method to pass in the query, storing the result in a variable. val results = spark.sql("SELECT * from my_keyspace_name.my_table")Use the returned data.
What file is Spark tagged with?
To build the program, we also write a Maven pom.xml file that lists Spark as a dependency. Note that Spark artifacts are tagged with a Scala version.
What was the main programming interface of Spark?
Note that, before Spark 2.0, the main programming interface of Spark was the Resilient Distributed Dataset (RDD). After Spark 2.0, RDDs are replaced by Dataset, which is strongly-typed like an RDD, but with richer optimizations under the hood. The RDD interface is still supported, and you can get a more detailed reference at the RDD programming guide. However, we highly recommend you to switch to use Dataset, which has better performance than RDD. See the SQL programming guide to get more information about Dataset.
How to get values from dataframe?
You can get values from DataFrame directly, by calling some actions, or transform the DataFrame to get a new one. For more details, please read the API doc.
What is Spark shell?
Spark’s shell provides a simple way to learn the API, as well as a powerful tool to analyze data interactively. It is available in either Scala (which runs on the Java VM and is thus a good way to use existing Java libraries) or Python. Start it by running the following in the Spark directory:
What can dataset actions and transformations be used for?
Dataset actions and transformations can be used for more complex computations. Let’s say we want to find the line with the most words:
What is a common data flow pattern?
One common data flow pattern is MapReduce, as popularized by Hadoop. Spark can implement MapReduce flows easily:
Can you use Spark to cache a 100 line text file?
It may seem silly to use Spark to explore and cache a 100-line text file. The interesting part is that these same functions can be used on very large data sets, even when they are striped across tens or hundreds of nodes. You can also do this interactively by connecting bin/spark-shell to a cluster, as described in the RDD programming guide.
What is the meaning of "back up"?
Making statements based on opinion; back them up with references or personal experience.
Is Spark a Scala repl?
In this context you can assume that Spark shell is just a normal Scala REPL so the same rules apply. You can get a list of the available commands using :help.
Can you invoke shell commands?
As you can see above you can invoke shell commands using :sh. For example:
What is RDD in Spark?
Resilient Distributed Datasets (RDD) is considered as the fundamental data structure of Spark commands. RDD is immutable and read-only in nature. All kind of computations in spark commands is done through transformations and actions on RDD’s.
Why do you need to count partitions in RDD?
of partitions. As it helps in tuning and troubleshooting while working with Spark commands.
What is Apache Spark?
Apache Spark is a framework built on top of Hadoop for fast computations. It extends the concept of MapReduce in the cluster-based scenario to efficiently run a task. Spark Command is written in Scala. Hadoop can be utilized by Spark in the following ways (see below): Start Your Free Data Science Course.
What is a pairwise RDD function?
This function joins two tables (table element is in pairwise fashion) based on the common key. In pairwise RDD, the first element is the key and second element is the value.
What does transformation filter need to be called on?
Transformation filter needs to be called on existing RDD to filter on the word “yes”, which will create new RDD with the new list of items.
What is Spark shell?
Spark shell provides a medium for users to interact with its functionalities. They have a lot of different commands which can be used to process data on the interactive shell.
Why is broadcast variable important?
Broadcast variable helps the programmer to keep read the only variable cached on every machine in the cluster, rather than shipping copy of that variable with tasks . This helps in the reduction of communication costs. In short, there are three main features of the Broadcasted variable: Immutable.
How to run Spark on Jupyter Notebook?
Open the terminal, go to the path 'C:sparksparkin' and type 'spark-shell'. Spark is up and running! Now lets run this on Jupyter Notebook.
How to install Anaconda on laptop?
To install spark on your laptop the following three steps need to be executed. Setup environment variables in Windows. Open Ports.
How to tell if PySpark is installed?
One may also ask, how do I know if Pyspark is installed? To test if your installation was successful, open Command Prompt, change to SPARK_HOME directory and type binpyspark. This should start the PySpark shell which can be used to interactively work with Spark.
How to get all columns in Spark dataframe?
You can get the all columns of a Spark DataFrame by using df.columns, it returns an array of column names as Array [Stirng].
How to get all data types in Spark?
In Spark you can get all DataFrame column names and types (DataType) by using df.dttypes and df.schema where df is an object of DataFrame. Let’s see some examples of how to get data type and column name of all columns and data type of selected column by name using Scala examples.