Activation Functions for Deep Learning
- Sigmoid Function. This is the sigmoid function. ...
- Hyperbolic Tangent Function. This is the hyperbolic tangent, or tanh, function. ...
- ReLU Function. The rectified linear unit, or ReLU, function is the most widely used activation function when designing networks today.
- Softmax Function. ...
How to choose an activation function for deep learning?
- Regression: One node, Linear activation
- Binary Classification: One node, Sigmoid activation
- Multiclass Classification: One node per class, Softmax activation
- Multilabel Classification: One node per class, Sigmoid activation
What is the best way to learn deep learning?
- Learn applied machine learning with a solid foundation in theory
- Clear, intuitive explanations take you deep into the theory and practice of Python machine learning
- Fully updated and expanded to cover PyTorch, transformers, XGBoost, graph neural networks, and best practices
What are the different types of activation functions?
- A. Identity Function: Identity function is used as an activation function for the input layer. ...
- B. Threshold/step Function: It is a commonly used activation function. ...
- C. ReLU (Rectified Linear Unit) Function: It is the most popularly used activation function in the areas of convolutional neural networks and deep learning.
- D. ...
- E. ...
What is an example of deep learning?
Deep learning methods can be used as generative models. Two popular examples include the Restricted Boltzmann Machine, or RBM, and the Deep Belief Network, or DBN. Two modern examples of deep learning generative modeling algorithms include the Variational Autoencoder, or VAE, and the Generative Adversarial Network, or GAN.
What is activation function explain with example?
The activation function defines the output of a neuron / node given an input or set of input (output of multiple neurons). It's the mimic of the stimulation of a biological neuron.Jun 9, 2020
What are activation functions used for?
An Activation Function decides whether a neuron should be activated or not. This means that it will decide whether the neuron's input to the network is important or not in the process of prediction using simpler mathematical operations.Mar 8, 2022
What is the purpose of activation function in neural networks?
The purpose of the activation function is to introduce non-linearity into the output of a neuron. We know, neural network has neurons that work in correspondence of weight, bias and their respective activation function.Oct 8, 2020
What is an activation function in machine learning?
Simply put, an activation function is a function that is added into an artificial neural network in order to help the network learn complex patterns in the data. When comparing with a neuron-based model that is in our brains, the activation function is at the end deciding what is to be fired to the next neuron.Dec 29, 2019
What is the best activation function?
The ReLU is the most used activation function in the world right now. Since, it is used in almost all the convolutional neural networks or deep learning. As you can see, the ReLU is half rectified (from bottom). f(z) is zero when z is less than zero and f(z) is equal to z when z is above or equal to zero.
What are the different types of activation function?
Popular types of activation functions and when to use themBinary Step Function. ... Linear Function. ... Sigmoid. ... Tanh. ... ReLU. ... Leaky ReLU. ... Parameterised ReLU. ... Exponential Linear Unit.More items...•Jan 30, 2020
Which are the characteristics of a good activation functions?
Properties of activation functionsNon Linearity.Continuously differentiable.Range.Monotonic.Approximates identity near the origin.Aug 26, 2020
Which activation function is the most commonly used activation function in neural networks?
Non-Linear Activation Function is the most commonly used Activation function in Neural Networks.Jan 23, 2021
Neural Network as a Function
At this point, I’d like to discuss another interpretation we can use to describe a neural network. Rather than considering a neural network a collection of nodes and edges, we can simply call it a function.
Why Do We Need Activation Functions?
The purpose of an activation function is to add some kind of non-linear property to the function, which is a neural network. Without the activation functions, the neural network could perform only linear mappings from inputs x to the outputs y. Why is this?
Different Kinds of Activation Functions
At this point, we should discuss the different activation functions we use in deep learning as well as their advantages and disadvantages
What Activation Function Should I Use?
I will answer this question with the best answer there is: it depends.
Which Activation Function Should You Use? Some Tips
Activation functions add a non-linear property to the neural network, which allows the network to model more complex data.
Activation Functions in deep learning
In artificial neural networks (ANN), the activation function helps us to determine the output of Neural Network. They decide whether the neuron should be activated or not. It determines the output of a model, its accuracy, and computational efficiency.
Properties that Activation function should hold?
Derivative or Differential: Change in y-axis w.r.t. change in x-axis.It is also known as slope. (Back prop)
Most popular activation functions
It is one of the commonly used activation function. The Sigmoid function was introduced to ANN in the 1990s to replace the Step function.
How to decide which one to choose or which is the right one?
Selection of activation functions is critical. So, which one to select!! There are no statement which indicates which activation function one can select. Each activation function as its own pro’s and con’s. All the good and bad will be decided based on the trail and error.
How does a neural network learn?
It is essential to get a basic idea of how the neural network learns. Let’s say that the desired output of the network is . The network produces an output . The difference between the predicted output and the desired output is converted to a metric known as the loss function ( ). The loss is high when the neural network makes a lot of mistakes, and it is low when it makes fewer mistakes. The goal of the training process is to find the weights and bias that minimise the loss function over the training set.
Why is the loss function high?
The loss is high when the neural network makes a lot of mistakes, and it is low when it makes fewer mistakes. The goal of the training process is to find the weights and bias that minimise the loss function over the training set. In the figure below, the loss function is shaped like a bowl.
What is tanh function?
It is also known as the hyperbolic tangent activation function. Similar to sigmoid, tanh also takes a real-valued number but squashes it into a range between -1 and 1. Unlike sigmoid, tanh outputs are zero-centered since the scope is between -1 and 1. You can think of a tanh function as two sigmoids put together.
Why are neural networks used?
Neural networks are used to implement complex functions, and non-linear activation functions enable them to approximate arbitrarily complex functions. Without the non-linearity introduced by the activation function, multiple layers of a neural network are equivalent to a single layer neural network.
Why is activation function important?
Simply put, an activation function is a function that is added into an artificial neural network in order to help the network learn complex patterns in the data. When comparing with a neuron-based model that is in our brains, the activation function is at the end deciding what is to be fired to the next neuron.
Why does the activation function vanishing gradient?
In other words, their gradients tend to vanish because of the depth of the network and the activation shifting the value to zero. This is called the vanishing gradient problem. So we want our activation function to not shift the gradient towards zero.
What is the softmax function?
This method is generally used for binary classification problems. Softmax: The softmax is a more generalised form of the sigmoid.
Why is activation important?
This is important in the way a network learns because not all the information is equally useful. Some of it is just noise. This is where activation functions come into picture. The activation functions help the network use the important information and suppress the irrelevant data points.
What is the first thing that comes to our mind when we have an activation function?
The first thing that comes to our mind when we have an activation function would be a threshold based classifier i.e. whether or not the neuron should be activated based on the value from the linear transformation.
What is a leaky Relu function?
Leaky ReLU function is nothing but an improved version of the ReLU function. As we saw that for the ReLU function, the gradient is 0 for x<0, which would deactivate the neurons in that region.
What is relu in deep learning?
The ReLU function is another non-linear activation function that has gained popularity in the deep learning domain. ReLU stands for Rectified Linear Unit. The main advantage of using the ReLU function over other activation functions is that it does not activate all the neurons at the same time.
What is the most widely used non-linear activation function?
The next activation function that we are going to look at is the Sigmoid function. It is one of the most widely used non-linear activation function. Sigmoid transforms the values between the range 0 and 1. Here is the mathematical expression for sigmoid-
What is a softmax function?
Softmax function is often described as a combination of multiple sigmoids. We know that sigmoid returns values between 0 and 1, which can be treated as probabilities of a data point belonging to a particular class. Thus sigmoid is widely used for binary classification problems.
What is a neural network without activation function?
A neural network without an activation function is essentially just a linear regression model. Thus we use a non linear transformation to the inputs of the neuron and this non-linearity in the network is introduced by an activation function.
Introduction
In a recent presentation I gave on the back-propagation algorithm, for neural network optimisation, the issue of differentiability came up with regard to certain activation functions.
Differentiation and differentiability
Firstly some background on differentiation and what it means to be a differentiable. For example, the function 𝑓 (𝑥) = 𝑥 is a function that maps real numbers to real numbers (𝑓 : ℝ → ℝ ). The function 𝑓 (𝑥) = 𝑥² is smooth and at every point is differentiable.
Activation functions for deep learning
The classical activation functions tanh and also the logistic sigmoid function are smooth functions throughout, if however you visualise some of the more recently introduced activation functions you will see that they are not smooth and have corners, although they are not differentiable throughout it is easy to find representations of these functions on the internet which suggest they are:.
Using activation functions for deep learning which contain non-differentiable points
Functions like ReLU are used in neural networks due to the computational advantages of using these simple equations over more traditional activation functions like tanh or the logistic sigmoid function.
Conclusion
Some may argue that if we are just going to specify the output at non-differentiable point anyway, why bother with the extra text and the notation required to explain that this point is not calculable. Others will say that we are abusing notation and that we are over simplifying things for a lay-audience.
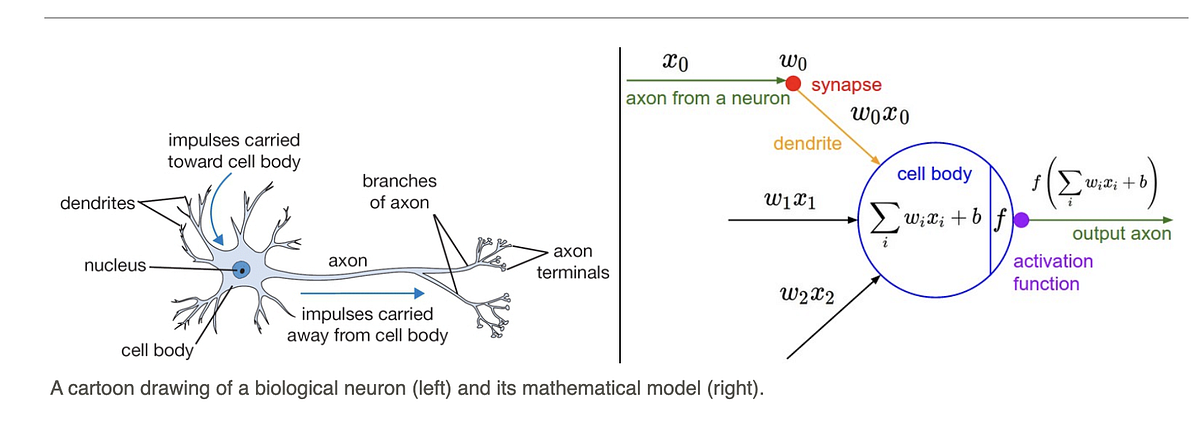
Neural Network as A Function
Why Do We Need Activation functions?
- The purpose of an activation function is to add some kind of non-linear property to the function, which is a neural network. Without the activation functions, the neural network could perform only linear mappings from inputs x to the outputs y. Why is this? Without the activation functions, the only mathematical operation during the forward propaga...
Different Kinds of Activation Functions
- At this point, we should discuss the different activation functions we use in deep learning as well as their advantages and disadvantages
What Activation Function Should I use?
- I will answer this question with the best answer there is: it depends. Specifically, it depends on the problem you are trying to solve and the value range of the output you’re expecting. For example, if you want your neural network to predict values that are larger than one, then tanh or sigmoid is not suitable for use in the output layer, and we must use ReLU instead. On the other hand, if we e…
What Is An Activation function?

How Does The Network Learn?
- It is essential to get a basic idea of how the neural network learns. Let’s say that the desired output of the network is . The network produces an output . The difference between the predicted output and the desired output is converted to a metric known as the loss function ( ). The loss is high when the neural network makes a lot of mistakes, and it is low when it makes fewer mistak…
Types of Activation Functions
- Linear Activation Function: It is a simple linear function of the form Basically, the input passes to the output without any modification.
Why Do We Need A Non-Linear Activation Function in An Artificial Neural Network?
- Neural networks are used to implement complex functions, and non-linear activation functions enable them to approximate arbitrarily complex functions. Without the non-linearity introduced by the activation function, multiple layers of a neural network are equivalent to a single layer neural network. Let’s see a simple example to understand why without non-linearity it is impossible to a…
Types of Non-Linear Activation Functions
- 5.1. Sigmoid
It is also known as Logistic Activation Function. It takes a real-valued number and squashes it into a range between 0 and 1. It is also used in the output layer where our end goal is to predict probability. It converts large negative numbers to 0 and large positive numbers to 1. Mathematic… - 5.2. Tanh
It is also known as the hyperbolic tangent activation function. Similar to sigmoid, tanh also takes a real-valued number but squashes it into a range between -1 and 1. Unlike sigmoid, tanh outputs are zero-centered since the scope is between -1 and 1. You can think of a tanh function as two si…